Введение
В этой статье мы расскажем о том, какие проблемы случаются с данными, как их решать, а также про наиболее часто используемые методы подготовки данных перед тем, как начать полноценный анализ данных.
Предварительная обработка данных является неотъемлемым этапом любого анализа данных (будь то сравнение средних значений двух выборок или построение статистической модели), поскольку качество данных и полезная информация, которую можно извлечь из них, влияет на точность получаемых результатов. Поэтому чрезвычайно важно, предварительно обработать данные, прежде чем приступить к полноценному анализу.
Пропуски в данных или недостающие данные
Пропуски в данных (missing data), часто вызывают ошибки при последующем анализе. Чаще всего, они возникают по причине неправильного ввода данных или при сокрытии информации.
На практике, мы часто сталкиваемся с ситуациями, когда пропуски в данных возникают по невнимательности респондентов при заполнении анкеты или невнимательности человека, который вносил данные в базу. Также, достаточно распространены случаи, когда пропуски в данных являются неслучайными. Например, когда исследуют выборку пациентов мужчин и женщин, и гинекологические показатели указывают только для женщин, оставляя пропуски в базе данных для пациентов мужского пола.
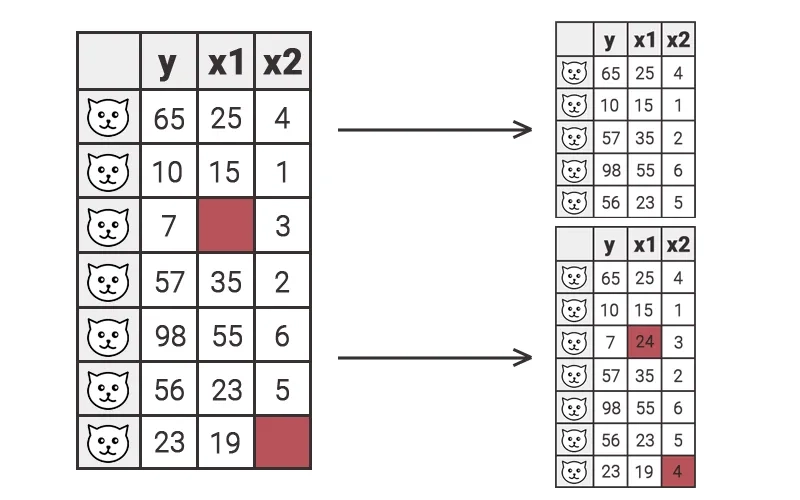
Два основных способа работы с недостающими данными:
1) Исключить наблюдение/строку
Это действительно рабочий метод, когда есть большой набор данных и вы знаете, что пропущенных данных примерно 1%. Этот процент не окажет сильного влияния на результат. Также исключение является рабочим методом, когда пропуски в данных неслучайны, как в примере выше с пациентами мужского и женского пола.
2) Заменить недостающие данные средним (или медианным) значением по столбцу
Наиболее распространенный вариант. Применяется, когда удаление строк может привести к потере большого количества информации.
Кодирование категориальных данных. Фиктивная переменная.
Не все алгоритмы машинного обучения работают с категориальными данными, в связи с чем возникает необходимость в преобразовании категориальных данных в фиктивные переменные.
Фиктивная переменная (dummy variable) — категориальная переменная, принимающая значения 0 и 1.
Категориальные данные могут быть трех типов:
- Бинарные или дихотомические переменные - переменные, которые имеют только два варианта здоров и болен, выиграл и проиграл и тд.
- Номинальные переменные без определенного ранжирования: город, цвет, бренд и тд.
- Порядковые переменные (имеют заданный порядок ранжирования), различные рейтинги, образование: начальное, среднее, высшее, оценка знаний: отлично, хорошо, неудовлетворительно и тд.
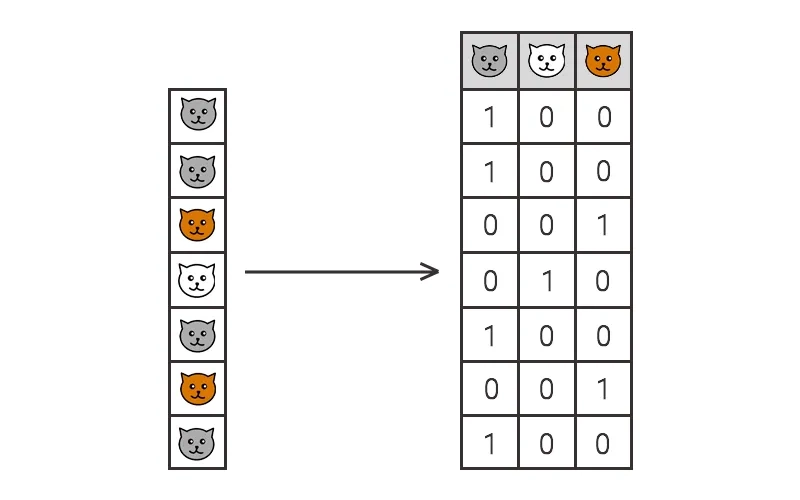
Зачастую, мы не можем передать в обработку качественные данные в исходном виде, и вынуждены их преобразовывать к числовому виду. Например, окрас котов. Казалось бы, можно преобразовать данные в 0,1,2 (например, серый – 0, белый – 1, рыжий– 2) и работать с ними. Но, в таком случае, может появиться неправильная интерпретация нашей кодировки, а именно, появится предположение, что этот порядок имеет значение, что на деле абсолютно не так.
Поэтому, правильным решением в данной ситуации будет разбить категориальную переменную на отдельные столбцы и закодировать данные бинарно в 0 и 1. Например, столбец с названием серый кот, будет состоять из 0 и 1, где 1 – это серый кот, а 0 – не серый (другой окрас).
Тестовая и обучающая выборки
В большинстве задач машинного обучения рекомендуется разделить выборку на две: тестовую(Test Set) и обучающую(Training Set).
Обучающая выборка – выборка, на которой модель обучается. Набор данных, который мы передаем нашей модели, чтобы изучить потенциальные закономерности и отношения.
Тестовая выборка – выборка для тестирования полученной модели, не участвуют в процессе обучения. Полученный, на тестовой выборке, результат мы сравниваем с фактическими значениями и исходя из этого, оцениваем точность нашей модели.

Обычно выборки делятся в пропорции Training Set – 80%, Test Set – 20%. Допустимы и другие пропорции, например 75:25.
Масштабирование данных
Многие алгоритмы машинного обучения работают лучше, когда признаки в данных имеют относительно одинаковой масштаб и близки к нормальному распределению. Именно поэтому, этот этап предварительной обработки не стоит игнорировать.
Зачем и когда масштабировать данные?
Не всегда нужно масштабировать данные, даже если они принимают абсолютно разные значения. Некоторые алгоритмы машинного обучения чувствительны к масштабированию функций, в то время как другие практически не зависят от него.
Важно:
- Масштабировать можно только весь столбец,
- Масштабирование не работает по строкам,
- Масштабировать данные нужно после разделения набора данных на тестовую и обучающую выборку. Это важно, потому что тестовый набор должен быть совершенно новым для оценки модели.
- Фиктивные переменные не нужно масштабировать. Во-первых, потому что бинарные данные, итак, лежат в диапазоне, близком к масштабируемому. Во-вторых, масштабирование помешает при интерпретации данных.
Два способа масштабирования данных: нормализация и стандартизация.
Нормализация — это метод масштабирования, при котором значения сдвигаются и масштабируются таким образом, что в конечном итоге они находятся в диапазоне от 0 до 1. Этот метод также известен как масштабирование минимум-максимум.
Берем минимум внутри столбца, вычитаем этот минимум из каждого значения внутри столбца, а потом делим на разницу между минимумом и максимумом по столбцу. В итоге получаем новый столбец со значениями между 0 и 1.
Формулы нормализации и стандартизации
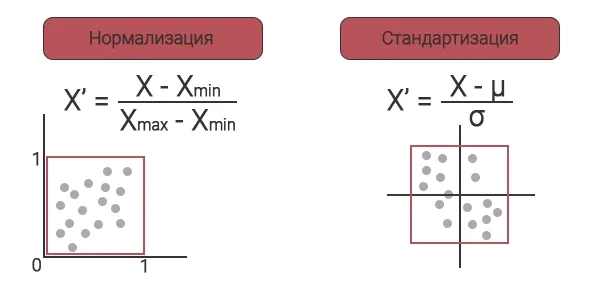
Стандартизация — еще один метод масштабирования, при котором значения центрируются вокруг среднего значения с единичным стандартным отклонением.
Это означает, что среднее значение атрибута становится равным нулю, а результирующее распределение имеет единичное стандартное отклонение. В этом случае значения не ограничены определенным диапазоном (экстремальные значения/выбросы могут оказаться снаружи).
Из каждого значения столбца вычитаем среднее по столбцу и делим на стандартное отклонение.
Когда выбирать стандартизацию, а когда нормализацию?
Стандартизация хорошо работает в случаях гауссовского/нормального распределения. Кроме того, в отличие от нормализации, стандартизация не имеет ограничивающего диапазона. Таким образом, даже если в данных есть выбросы, стандартизация не повлияет на них.
Нормализация полезна, когда мы не знаем точное распределение данных, или знаем, что оно не соответствует гауссовскому/нормальному распределению.
Не существует жестких правил, указывающих, когда следует нормализовать или стандартизировать данные. Можно построить две модели: с нормализованными данными и со стандартизированными данными, сравнить точность и выбрать лучший результат.
Статистическая обработка данных на заказ
Мы оказываем помощь в статистических расчетах для научных статей, диссертаций или маркетинговых исследований. Свяжитесь с нами одним из удобных способов, чтобы обсудить детали:
WhatsApp: +7 (919) 882-93-67
Telegram: birdyx_ru
E-mail: mail@birdyx.ru
- Подберем корректные методы обработки и анализа данных
- Преобразуем данные в удобный для анализа вид
- Проведем необходимые вычисления
- Опишем и оформим результаты: выводы, таблицы, графики.
Проведем быстрый и качественный статистический анализ данных!
Мы растем, развиваемся, постоянно работаем над автоматизацией аналитических процессов, чтобы предоставлять Вам качественную аналитику оперативно и по доступной цене.